Modern Fine-Tuning
Modern Fine-tuning
This is a non-comprehensive review of modern LLM fine-tuning. These notes are a way for me to review for research roles. If you’re hiring – reach out!.
TL;DR: Full fine-tuning updates all model parameters, maximising performance but requiring high memory and compute. Parameter-efficient fine-tuning (PEFT) attemps to reduce trainable parameters while maintaining good performance.
Full Fine-Tuning
Full fine-tuning updates all the parameters of a (typically pre-trained) deep neural network on a new, task-specific dataset. This approach generally yields the highest performance but is computationally intensive and requires considerable VRAM since all gradients must be tracked for all parameters. When the new task has limited data, full fine-tuning can lead to overfitting and may result in the loss of general knowledge from pre-training (catastrophic forgetting).
If \(N\) is the number of parameters and each parameter takes \(B\) bytes (e.g. 4 bytes for FP32 or 2 bytes for FP16), then for SGD and Adam (which stores two extra tensors per parameter – momentum and moment), the total static memory footprint (ignoring activations) is given by:
\[\text{Memory}_{SGD} = (\text{params state} + \text{gradients state}) \times N \times B = 2NB\] \[\text{Memory}_{adam} = (\text{params state} + \text{gradients state} + 2 \times \text{optimizer state}) \times N \times B = 4NB\]Importantly, this equation does not include additional memory required for activations during training, which depends on batch size, model architecture, and CUDA overhead.
Numerical Precision Considerations
- FP32: High precision but high memory usage.
- FP16: Lower memory usage but limited exponent range, which can cause numerical issues.
- BF16: BF16, or bfloat16, uses an 8‐bit exponent like FP32, unlike FP16 which has only a 5‐bit exponent. Neural networks often produce very small and very large values—particularly in gradients during backpropagation—so having a wider exponent range is crucial to avoid underflow or overflow. Although BF16 offers less precision in the mantissa compared to FP16, its broader range makes it more robust in capturing the full scale of numbers that arise during neural network training and inference.
- Mixed Precision Training: Uses lower precisions for most operations while keeping FP32 for critical computations.
Parameter-Efficient Fine-Tuning (PEFT)
Fine-tuning all parameters is costly. PEFT methods reduce the number of trainable parameters while maintaining good performance.
Quantized Fine-Tuning
Quantization reduces memory usage by storing model parameters, gradients, and optimizer states in lower bit-width formats (e.g., 8-bit or 4-bit). This reduces both memory footprint and computational load but can affect training stability and model performance.
Adapters [Houlsby et al., 2019]
![Adapters [Houlsby et al., 2019]](/assets/images/finetuning/adapter.png)
Adapters insert small trainable modules between layers while freezing the original weights. This method introduces additional parameters but allows for efficient fine-tuning with minimal computational overhead.
Low-Rank Adaptation (LoRA) [Hu et al., 2021]
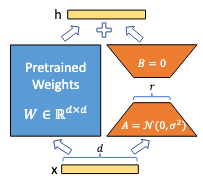
LoRA updates weights using low-rank matrices:
\[\Delta W = AB\]where \(A \in \mathbb{R}^{d \times r}\) and \(B \in \mathbb{R}^{r \times k}\) with \(r < \min(d,k)\). LoRA significantly reduces trainable parameters and allows merging the updates back into the original model after training.
Variants
- QLoRA [Dettmers et al., 2023]: Combines low-rank decomposition with quantization for additional memory savings.
- DoRA [Liu et al., 2024]: Decomposes weights into a magnitude and direction. Uses a separate trainable vector for magnitude and LoRA for the direction. This adds a tiny bit of extra parameters but is shown to be more stable.
Prefix-Tuning [Li and Liang, 2021]
![Prefix-Tuning [Li and Liang, 2021]](/assets/images/finetuning/prefix.png)
Prefix-tuning prepends trainable soft tokens to the input sequence at each layer, keeping LM weights frozen. A simplified version, Prompt-Tuning [Lester et al., 2021], applies this only to the embedding layer. This method increases sequence length but allows for fast adaptation to new tasks.
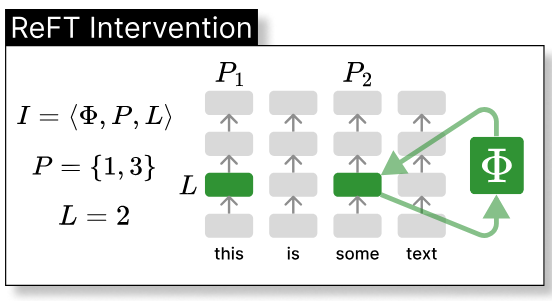
Representation Fine-Tuning (ReFT) [Wu et al., 2024]
ReFT applies task-specific interventions to hidden states at predefined positions and layers. LoReFT combines LoRA with ReFT, updating hidden states as:
\[h' = h + R^T(W h + b - R h)\]where \(R \in \mathbb{R}^{r \times d}\) and \(W \in \mathbb{R}^{r \times d}\) are low-rank matrices.
Summary: Fine-Tuning Trade-offs
| Method | Pros | Cons | Trainable Parameters |
|---|---|---|---|
| Fine-Tuning | Maximises performance, Utilises all model capacity, Simple | High memory/computation cost, Risk of overfitting | 100% |
| Adapters | Low additional parameters, Modular (switchable adapters) | Increases total parameter count, Performance depends on design | ~3% |
| LoRA | Reduces trainable parameters, Merges back into base model | Hyperparameter sensitive, May not match full fine-tuning performance | 0.5-1% |
| Prefix-Tuning | Switchable prefixes for different tasks | Increases sequence length | 0.1% |
| ReFT | Minimises parameter changes, Hybrid of LoRA/adapters | Requires careful tuning (layer/position selection) | 0.025-0.05% |
Conclusion
The choice between full and partial fine-tuning depends on available resources and task requirements. Full fine-tuning maximises performance but is expensive. PEFT methods like Adapters, LoRA, and ReFT provide efficient alternatives for scenarios with limited data or compute resources.
Citations
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., de Laroussilhe, Q., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. arXiv:1902.00751.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314.
Liu, S.-Y., Wang, C.-Y., Yin, H., Molchanov, P., Wang, Y.-C. F., Cheng, K.-T., & Chen, M.-H. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv:2402.09353.
Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv:2101.00190.
Wu, S., Liu, S., & Ruder, S. (2024). ReFT: Representation Fine-Tuning for Language Models. arXiv:2401.12345.